简介
书接上文,在上一章节中,我详细的分析了市场上已经落地应用的部分商用方案,也针对自己的实际需求进行了思考,设计了适合需求的编码规范和编码形式。在本章节中,我将会分享一下Discode的生成和识别过程和技术细节。
目录
- 生成Discode
- 识别Discode
- Github仓库
- 编后语
- 版权声明
生成Discode
如何生成图形编码?
在前面的设计原型中,Discode中包含四个定位点的设计。按照设计Discode的定位点类似于微信小程序码的定位点,基础元素是由一个圆环和一个圆点组成的图案。

之后会将其等距离的放置在图形编码的四个角上,用于图形的定位,如下图所示。

确定好定位点之后,我们就需要生成我们的图形编码了。图形编码包含两个部分:
一、用什么规则来代表数据?
参考条形码的设计,我决定通过点与线来分别代表0和1。之所以会有这样子的想法,是我认为在之后的学习研究识别过程中,点与线的识别应该会有更多现成的代码可以参考学习,不用自己再花大量时间来研究。
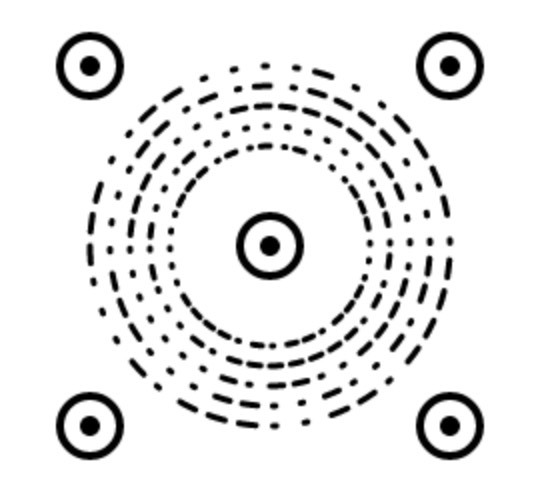
基于这种想法,通过简单的编程在canvas上生成了上图的DEMO图形,拥有五个定位点与按照一定规则环状点线的编码区所组成的Discode。(之所以在图形的中心也包含一个定位点,主要是当时想用来确认圆心是否能够被计算正确,所以增加的辅助图形,在技术验证后就被品牌Icon代替。)
二、存储数据量要设计多大?
在之前的原型设计中,我曾经分析过小程序拥有多种容量的设计,比如36线、72线、144线等设计。通过增加线密度来增加图形的数据承载量。因此我也对此进行了一些简单的实验。
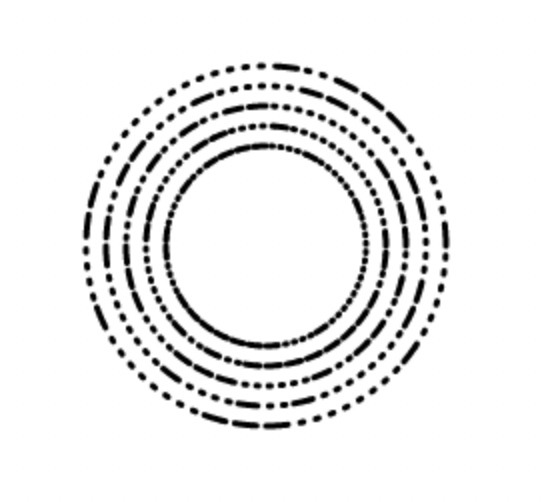
上图是每隔五度绘制一位数据的72线版本的Discode,可以很容易的看到,在内圈的1-3层,由于图形之间的间隙过小,很容易产生图形与图形间粘连在一块的问题,特别是第二圈右下角的多线段连在一块很难辨别的问题。
题外话
那为啥微信小程序可以支持72线?
通过观察微信小程序的设计规范可以发现,之所以元信息区并不是从最内圈开始的原因:就是为了解决72线可能会导致图形绘制过于密集,导致编码图形难以被识别和处理。而选择了往外移了几圈,才开始进行实质性的编码。
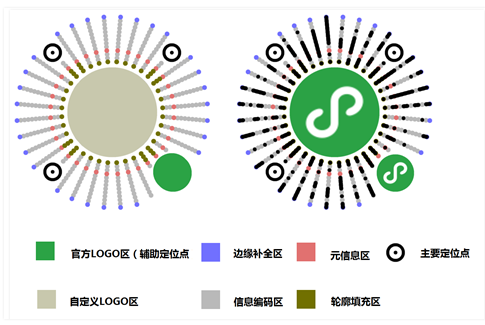

对比实际编码出来的图形,我们可以发现,为了美观考虑,小程序码在元信息区往圆心方向的编码区其实只有36线,即10度才记录一个编码,只有在元信息区才开始使用72线,即5度进行一个编码。
那问题就迎刃而解了,要么就是将实际数据编码区往外移,要么就是减少单圈编码密度。最终我还是选择了减少单圈编码密度作为我的解决方法,之所以选择这个方法就是图省事,简单快速的解决问题,不然将编码区外移又需要耗费一部分的时间来重新设计编码规范,我着实是不想这么干。
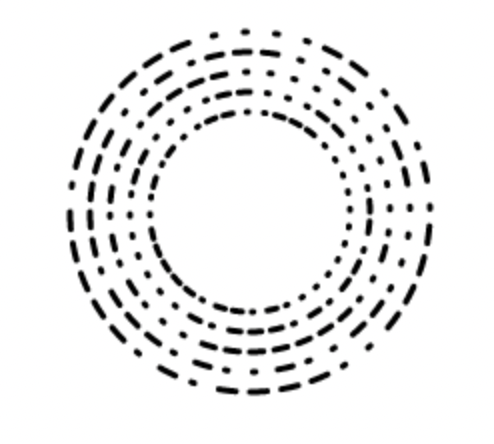
增大到10度一编码后,图形的视觉效果就好多了,另外也部分程度上的解决了图形粘黏的问题。解决了编码问题后,我们只要将定位点、编码区组装起来就是我们设计出来的Discode了。
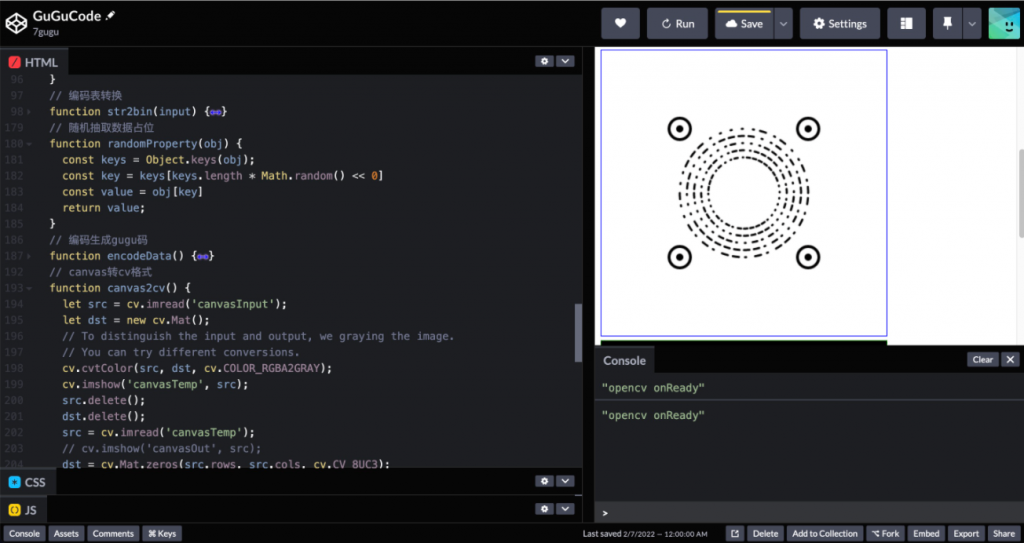
其实到这一步Discode就已经生成完成了,只要在中间预留的空白处填上我们希望填充的Logo即可。
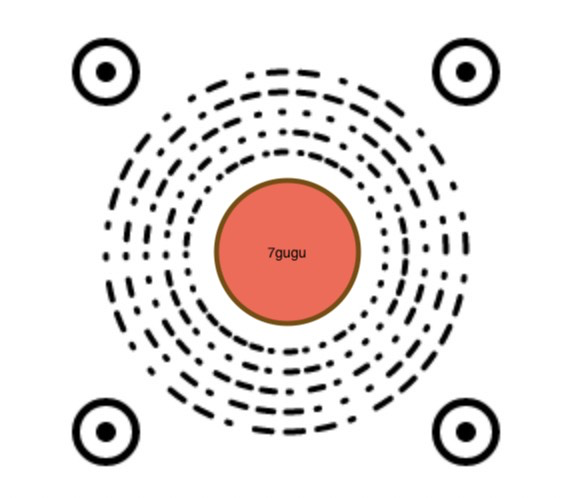
识别Discode
识别Discode主要有以下的几个步骤:
- 使用Hough Circle获取定位点的圆心坐标
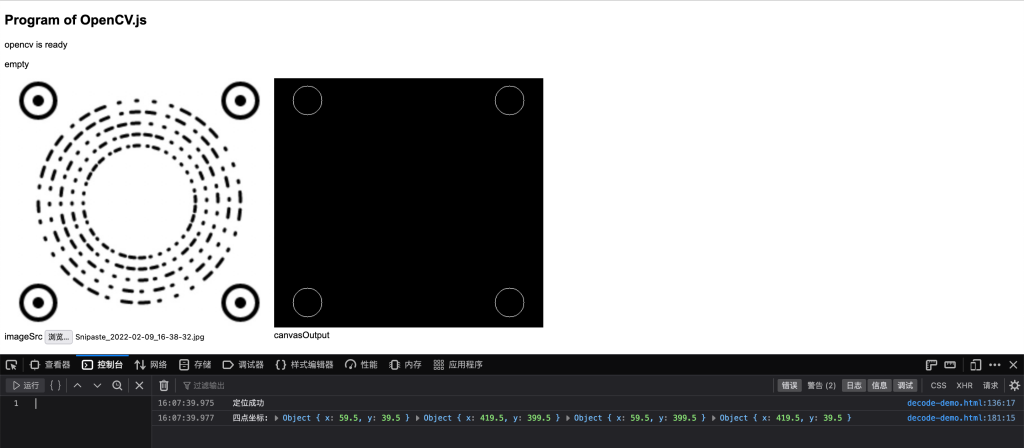
通过Hough Circle Transform获得四个定位点的相对于图片的位置信息。
- 通过四个定位点计算编码区圆心位置
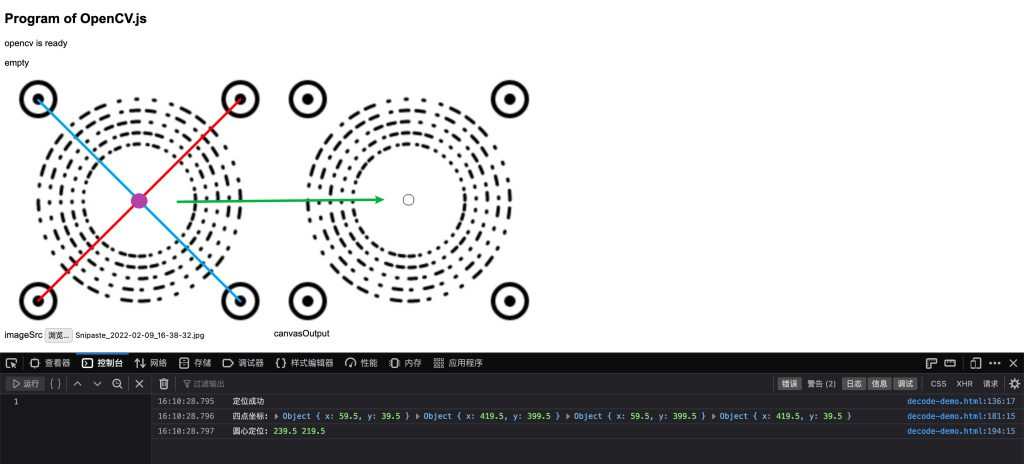
接下来连接对角点,形成两条线段(红线与蓝线),计算交点位置。
如上图顺序对应0-3的四个坐标代入公式计算得出圆心坐标。
- 设置ROI(Region of interest)识别指定区域
Discode的编码起点如下图所示:
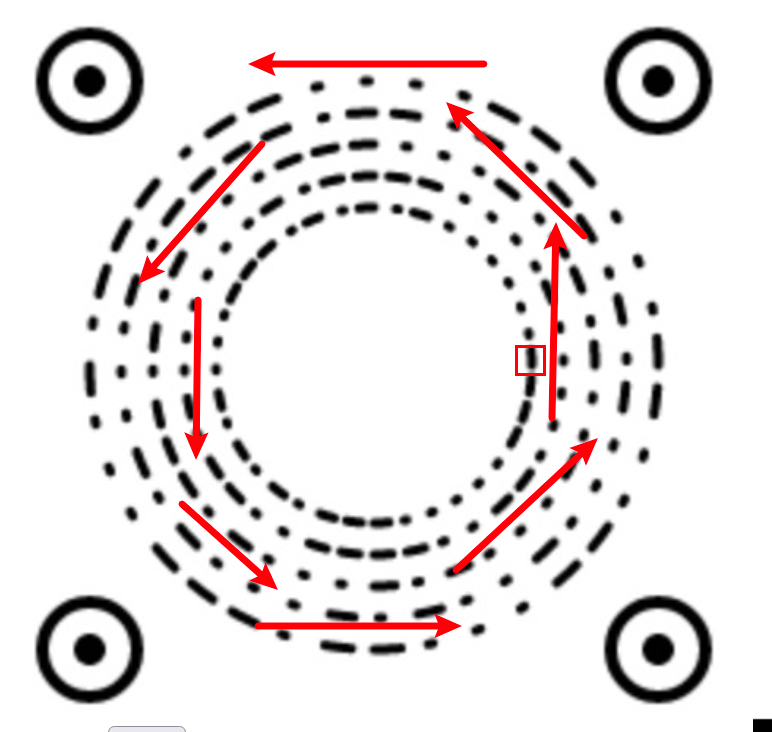
Discode从上图的矩形框中开始生成第一位编码,然后在相同半径内沿着逆时针方向(红箭头),生成接下来的编码,当一圈编码完成后就自增半径,开始第二圈的编码直到编码五圈为止。
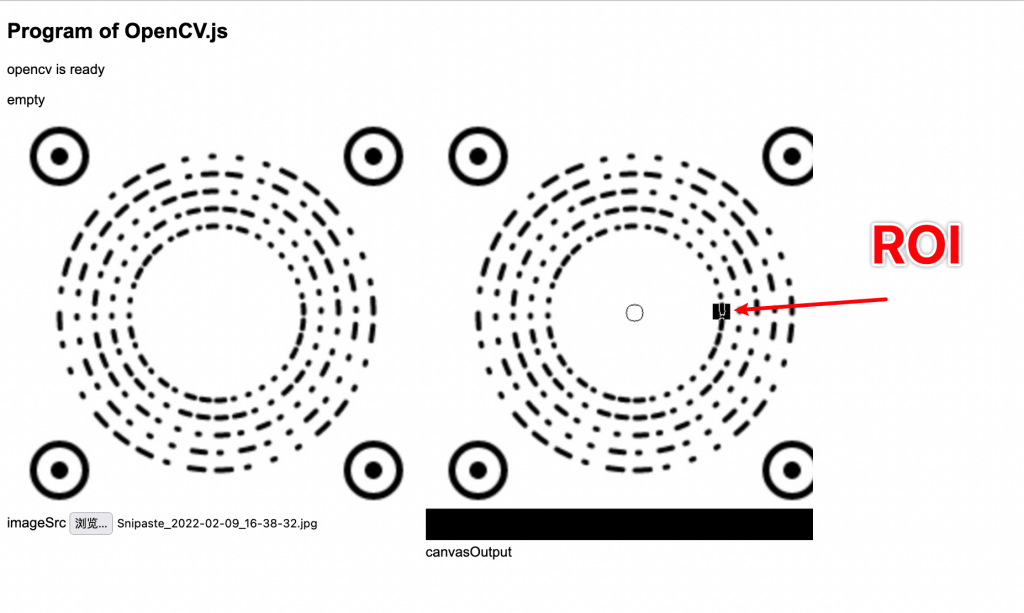
而识别其实就是逆向这个过程,如上图设置图像的ROI到图像的编码开始点,然后逆时针一个一个识别,一圈一圈识别,直到识别完成。
- 使用Canny edge detection获得识别区的轮廓
在上一步中,我们设置了图像的ROI,接下来我们要做的就是计算这个ROI内的图形到底代表的是0还是1。
识别的核心原理:计算ROI区域内的图形的面积。
之所以我们可以这么做,是因为我们已知ROI的面积信息,我们也知道长线段占用的面积理应大于短线段的常理,基于这两个信息,我们只要计算ROI内图形面积,并通过经验设定一个阈值来判定是长线段还是短线段。知道线段类型后,转换成0和1就水到渠成了。
这里我们引入了Canney边缘检测,通过边缘检测获得ROI内图形的轮廓数据。
- 通过contourArea函数计算轮廓面积
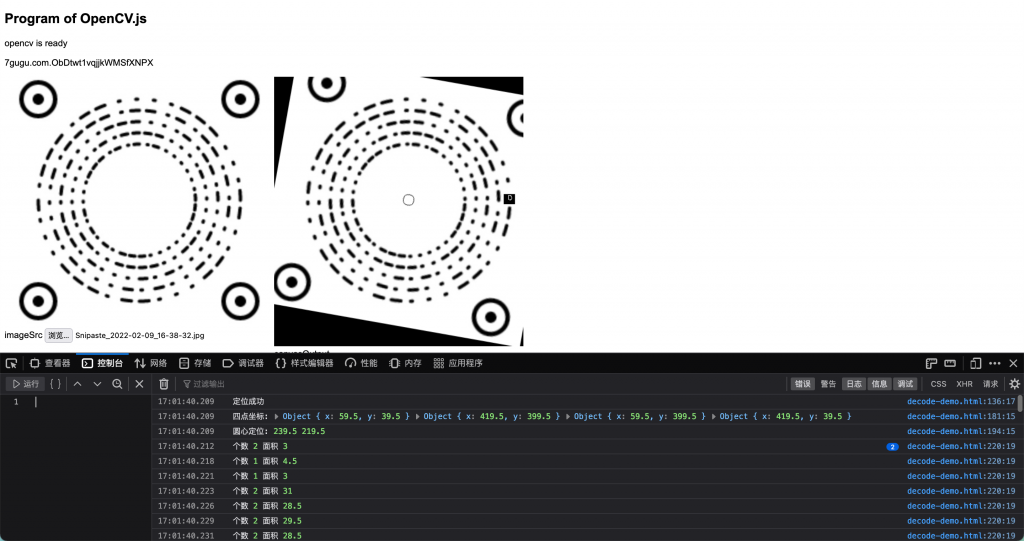
获得轮廓数据后,我们就可以计算出ROI中的闭合图形个数以及总面积信息,之所以有时候个数会大于1,是因为有时候ROI会重复识别到上一个图形的边缘,导致到污染了识别区。不过由于这种现象仅仅发生于长线段的交接处才会发生,且数据影响不大,因此我也没有做进一步的处理。如果要继续优化,可以继续精细化ROI区域,使得覆盖率提高。或者调整生成图形算法,加大线段之间的间隙,避免互相粘黏。
- 判定图形代表0或1
通过多次的实验可得,短线段的占用的面积必定小于10,大于10的必定是长线段。因此在这里使用10作为阈值,用于判定ROI内的图像是代表0或1。
- 分割 & 转换
将每个图像代表的二进制数值存入数组当中并将其按照6bit为一位通过编码字典,重新转换成可阅读的字符串。
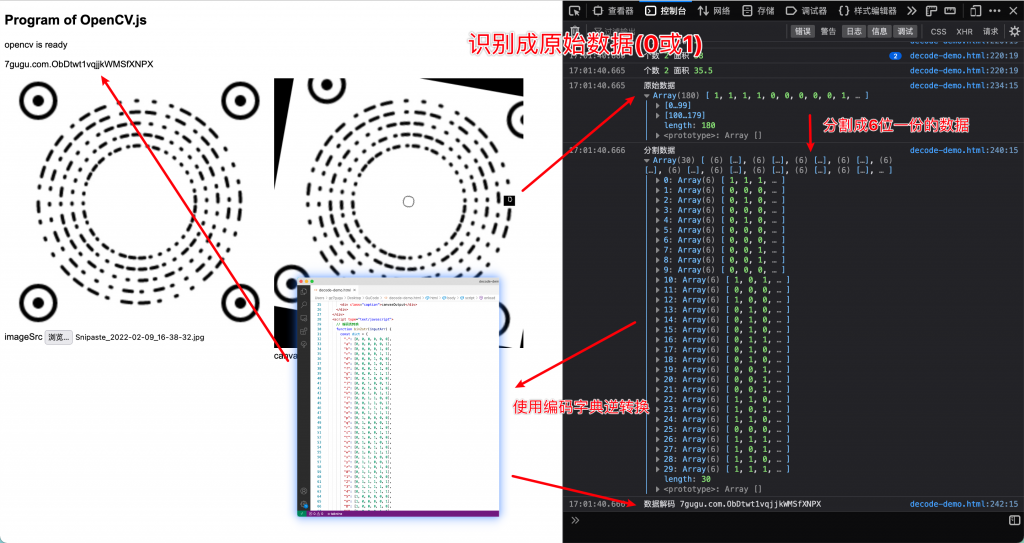
- 输出结果
由于有时候编码的字符不一定会用完全部可用编码位,因此还会在有效编码后面加入一些随机数据作为填充,使得图形更加美观。
Github仓库
https://github.com/7gugu/Discode
仓库中包含了完整的生成和识别图形代码,可以自行运行学习一下。实测通过FireFox 100是可以正常运行的。
编后语
至此整个Discode系列就全部更新完成了。原来在这个部分我思考了很久,写了几个版本的内容,先是是过拆分成两个章节来慢慢讲解,也试过回溯历史结合QRCode来阐述为啥我要这么做,但效果都不尽如意,过于的繁琐冗余,最后还是秉着少即是多的原则,缩减成一章来讲解。五月中的时候恰好碰上了组内的技术分享,有幸向其他同事分享了我的这个想法,也得到很多宝贵的建议。之后由于毕业设计和工作上的琐事,使得进度很慢,对此向期待这篇技术分享的朋友说声抱歉。接下去我应该会专注于wasm和三维建模上,希望以后可以投入游戏产业,继续实现个人梦想。
版权声明

本作品采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。
干得好,加油
关于苹果的Clips Code,是否有公开资料可以知道它的还原方法呢?
没有,目前只能猜测
质量很高
谢谢夸奖,欢迎常来作客